Muchas veces, en las clases de programación, nos encuentro a los profes haciendo mucho énfasis en que los alumnos "entiendan el problema" antes de comenzar a programar. Al escribir esto, imagino que muchos, posiblemente la mayoría, de mis lectores habrán pensado: "¡Obvio!".
Sin embargo, yo miro mi trabajo profesional y la verdad es que no funciona tan así, y no creo que eso sea porque lo hacemos mal. Muy por el contrario, muchas veces eso pasa justamente porque estamos trabajando bien, no es un error metodológico, es un feature de nuestra metodología de desarrollo.
¿Cómo es eso? Bueno, para empezar busquemos un poco de equilibrio en nuestra afirmación. Por supuesto que uno tiene que tener una idea de lo que quiere hacer, y por supuesto que como profes frecuentemente nos encontramos en situaciones en las que le queremos pedir al estudiante que c fa tome un tiempo para entender antes de lanzarse a escribir código. Sí, pero... ¡hasta ahí!
Y aunque tal vez parece demodé discutir esto a 16 años de la publicación del manifiesto ágil, yo creo que seguimos teniendo una contradicción grande frente a nosotros. Imagino que si yo digo que eso es pensar en cascada, a muchos les parecerá anacrónico, nadie piensa ya en desarrollar software en cascada. Los más jóvenes ni saben de lo que estoy hablando. Pero al mismo tiempo, imagino que a muchos (¡todavía!) les da urticaria si escuchan a alguien decir que programa sin entender bien el problema que quiere resolver o que se mandó a codear sin tener un diseño en mente... es que en algunas prácticas, en algunos discursos, en muchos vicios todavía persiste la idea de tener "el análisis primero".
En un desarrollo profesional, no suele pasar que viene alguien con un enunciado inmutable de lo que hay que hacer, como pasa en un parcial. Al contrario, nuestro product owner va puliendo el concepto del producto a medida que avanza el proyecto: se construye una etapa, se enfrenta a los usuarios con estas ideas, se mide el uso, y se toman decisiones que pueden cambiar lo que se hizo antes. A menudo pasa que los programadores negociamos con el product owner, por ejemplo proponiendo alternativas que son más fáciles de desarrollar.
Y si bien muy posiblemente es quien conoce el dominio, los potenciales usuarios y sus problemas quien guía la definición de qué es lo que queremos del producto, nunca lo hace de manera unidireccional, viendo al resto del equipo de desarrollo como una caja negra que convierte sus especificaciones en software funcionando. En cambio, la definición final del rumbo surge de un proceso interactivo, multidisciplinar, en la que intervienen personas con diferentes visiones y conocimientos: dominio del problema, tecnología (que no es sólo programación), user experience, etc.
Sí, lo sé. Nada nuevo bajo el sol. ¿O sí? ¿Será que ya esos conceptos cascadosos ya están olvidados? ¿O nos sigue pasando que debajo de los nombres nuevos seguimos pensando el desarrollo de software como una cadena de montaje?

Thursday, 31 August 2017
Saturday, 18 July 2015
Wisit15 - Proponé tu charla
Wisit15 - 19 de septiembre - Universidad de Quilmes
Se reciben propuestas de charlas y trabajos para presentar en el Workshop
- TRACK INVESTIGACIÓN
Trabajos científicos que tengan como objetivo mejorar la forma en que desarrollamos software o formamos nuevos profesionales, favoreciendo la interacción entre el ámbito académico y el industrial.
- TRACK EXPERIENCIAS
Exposiciones sobre experiencias concretas en la aplicación de tecnologías y metodologías innovadoras en el ámbito industrial y docente.
Enviá tu propuesta a info@uqbar.org
- HANDS ON
¿Estás utilizando en una tecnología innovadora? ¿Te animás enseñarnos a dar los primeros pasos en un par de horas?
Enviá tu propuesta a info@uqbar.org
- MOSTRÁ TU PROYECTO
¿Estás trabajando en un proyecto novedoso? ¡Vení y contanos tus ideas!
No se requiere inscripción previa, acercate con tu propuesta el día de la conferencia. En caso de dudas mandá tu consulta a info@uqbar.org
Saturday, 6 June 2015
Tutorial: Language Development with XText: A Logo example - Part III: The Interpreter
In the first post of this tutorial series we have introduced a little bit xtext and discussed in general the different approach for implementing the runtime part of your language.
In this post we will show an example Interpreter for the Logo language, for which we have already seen its set of instructions and its xtext grammar in the second post.
So now we will see the interpreter's code.
But before that
Basically we don't need to do much, since the canvas (instance of TortueCanvas) already has methods for this functionalities.
So on each type of movement we call a different method.
The interesting part is that we need to evaluate the "amount" field of the movement.
Because it could be a number, but it also could be a variable reference.
So basically we need to pass that object also through the interpreter.
This is a pretty common pattern. Probably all attributes of all the semantic class will need to eventually get evaluated by the interpreter.
So it's kind of a recursive pattern.
Evaluate() here is also an extension methods, with multiple dispatch.
Because different classes behave differently for evaluating them.
We will get back to evaluate() later.
Again we are adding a "evalBool" method to the boolean condition.
Notice what's funny here is that this means that the Logo IF statement is implemented using Java/Xtend if statement. Which is obvious, but well, just something to be aware of.
As our interpreter is written in Java/Xtend then your language runtime can rely on already implemented functionality from the JVM, for example garbage collection, and also the stack execution model !
You don't need to write that up from scratch or implement.
At least for a language that shares the same execution model as JVM.
Here is the repeat implementation:
But before that we need to push the new context into the stack.
And after that popping it so we will use the previous context.
So our interpreter has a stack attribute besides the canvas
var stack = new Stack<Map<PARAM, Double>>
Notice that the stack is a map of PARAM and a Double.
This means that each stack element (context) has the declaration of the parameters, plus their actual values.
The part that changes is the value, the double.
So now we can see how the createContext() works:
First it evaluates the closure (+, /, *, etc).
Then it simply changes the targetVariable's "value" to point to the new value.
The next interesting part here is the "asValue" method, because the function returns a double object, but we cannot set a double to "targetVariable.value".
Which is the MAKE.value property, of type EXPRESSION.
So we need to create a new EXPRESSION object with the double number.
This is interesting because up until now we never created new instances of our semantic model.
All of the instances were created by Xtext itself based on the input file, while parsing it.
So if you need to create new objects you need to use a Factory class that is also automatically generated by XText.
In this post we will show an example Interpreter for the Logo language, for which we have already seen its set of instructions and its xtext grammar in the second post.
So now we will see the interpreter's code.
But before that
Overview of the Logo Semantic Model
Lets analyse a little bit what's a logo program once it has been parsed and validated and then the semantic model instances are created.
For that it's useful to understand the classes XText generated.
Here's a full class diagram of the semantic model.

Here's a full class diagram of the semantic model.
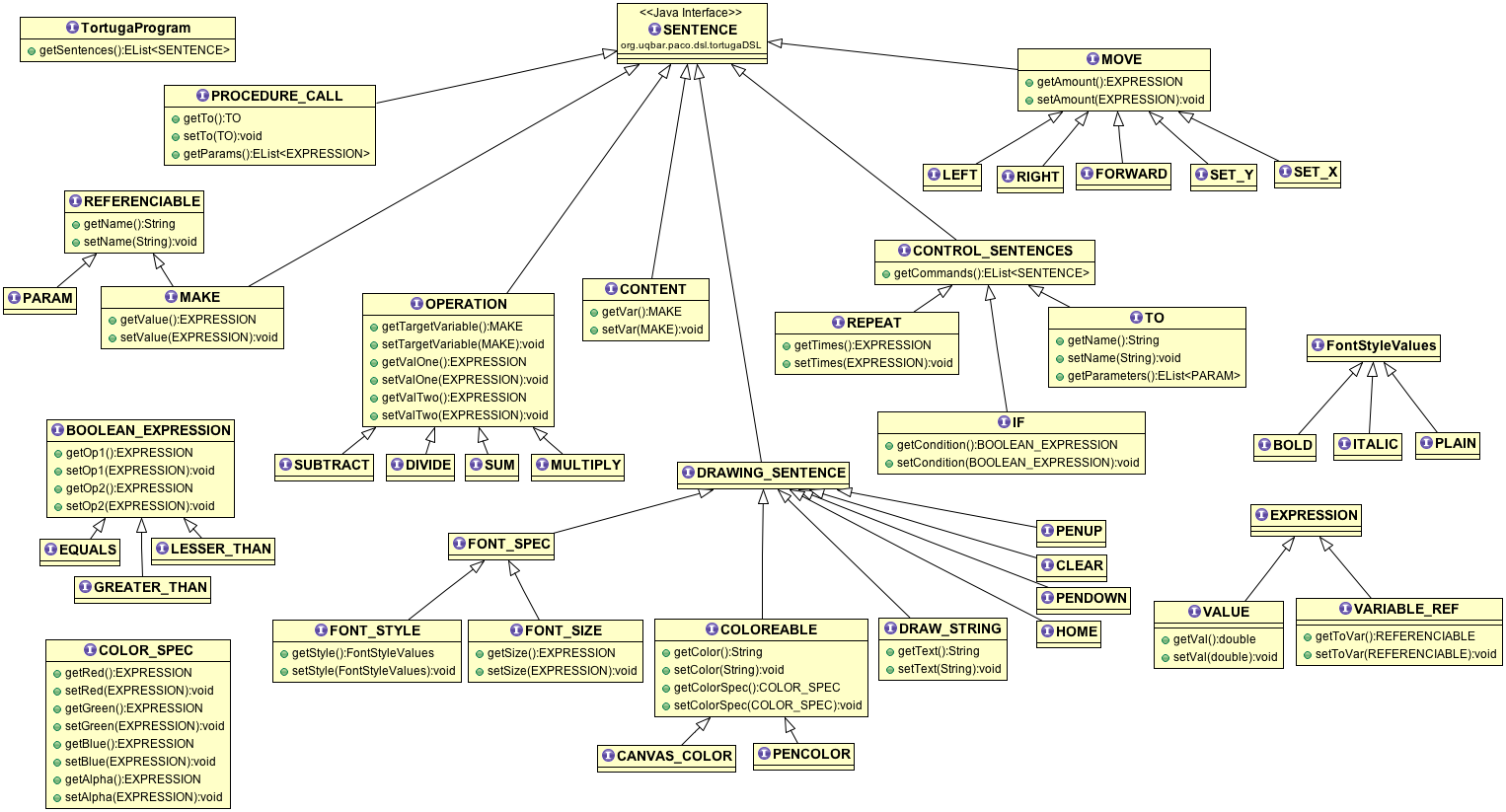
The root element is the TortugaProgram (the first grammar rule).
A program has a list of SENTENCES (grr.. to comply with the syntax we defined rules that are uppercased and now they just don't follow the standard java class names).
Then there are a couple of different SENTENCES like REPEAT, IF, MAKE, etc.
The Interpreter
What's an interpreter ?
In its simplest way, an interpreter for an XText language is just a class that, given an input file:
- Calls XText so that it parses the file (validating and linking) and returns back an instance of the root model (TortugaProgram in our case)
- Then does something with those objects
It could be a simple class with a Main.
class MyInterpreter {
def static void main(String[] args) {
val fileName = args.get(0)
val uri = URI.createURI(fileName)
val injector = new MyDslStandaloneSetup().createInjectorAndDoEMFRegistration
val resourceSet = injector.getInstance(XtextResourceSet)
val resource = resourceSet.createResource(uri)
resource.load(#{})
val model = resource.contents.get(0) as MyModel
new MyInterpreter().interpret(model)
}
def void interpret(MyModel model) {
// DO SOMETHING HERE ...
}
}
Then you could package it along with all its dependencies (that would need a new blog post) and then anyone could use it like:
java -cp .... classpath_here... org.uqbar.tutorial.xtext.MyInterpreter myFile.tortu
You could also provide a script to hide away the java command
./logo myFile.tortu
Integrating it into Eclipse
Instead of creating a Main class for headless execution, as the interpreter is just java code, you could integrate it with the Eclipse IDE, so that one can use the text editor for writing code in your language and then just "run" it from the IDE itself.
This can be done by extending an specific eclipse extension point for launch shortcuts (in case you want to show it as part of the "Run" menu), providing a class, icon, and a filter so that it will only apply for your language file extension.
Here is a sample xml from our plugin.xml
<extension
point="org.eclipse.debug.ui.launchShortcuts">
<shortcut
class="org.uqbar.paco.dsl.ui.TortugaDSLExecutableExtensionFactory:org.uqbar.paco.dsl.tortuga.ui.launch.LaunchTortugaShortcut"
icon="icons/tortuga.png"
id="org.uqbar.paco.dsl.tortuga.ui.launchTortuga"
label="Tortuga"
modes="run">
<contextualLaunch>
<enablement>
<with variable="selection">
<count value="1"/>
<iterate
ifEmpty="false"
operator="and">
<adapt type="org.eclipse.core.resources.IFile"/>
<test property="org.eclipse.debug.ui.matchesPattern"
value="*.tortu"/>
</iterate>
</with>
</enablement>
<contextLabel
mode="run"
label="Run Tortuga"/>
</contextualLaunch>
</shortcut>
</extension>
And then the Launch class has code similar to the main we have seen, but delegates the actual interpreting logic to an interpreter class.
class LaunchTortugaShortcut implements ILaunchShortcut {
@Inject
private IResourceForEditorInputFactory resourceFactory;
override launch(ISelection selection, String mode) { }
override launch(IEditorPart editor, String mode) {
val input = editor.editorInput
if (editor instanceof XtextEditor && input instanceof FileEditorInput) {
val resource = resourceFactory.createResource(input)
resource.load(newHashMap())
val program = resource.contents.head as TortugaProgram
new TortugaInterpreter(canvas).exec(program)
}
}
def getCanvas() {
TortugaView.getInstance.canvas
}
}
It basically gets the current editor's file and then calls Xtext to load it, which will do all the parsing and validation.
With the model parsed into a TortugaProgram, it creates a new TortugaInterpreter and executes the program.
In our case the interpreter receives a Canvas in which Tortue will paint.
That's all for the skeleton of our interpreter.
The interpreter itself
Now we need to implement the execution (the runtime semantic) for each of the classes of our semantic model.
Let's start from top to down
Interpreter class and evaluating the root model
Interpreting a Logo program would be basically to execute each of its sentences.
So here's a sample implementation:
class TortugaInterpreter {
TortueCanvas canvas
new(TortueCanvas canvas) {
this.canvas = canvas;
}
def dispatch void exec(TortugaProgram p) {
canvas.newCommand
p.sentences.forEach[s | s.exec ; canvas.repaint ]
}
// ******************************
// ** EXECs: here one multi method per SENTENCE CLASS
// ******************************
def dispatch exec(...) { ... }
def dispatch exec(...) { ... }
def dispatch exec(...) { ... }
}
What we see here is that evaluating a TortugaProgram is to:
- reset the canvas
- evaluate each of the "sentences"
We can see that we are using multiple dispatch methods.
This is a pretty cool feature of xtend that is really useful for language interpreters along with extension methods.
Since we cannot touch the semantic model classes because they are generated, we will use extension methods, to add behaviour to them, and use it as if they were methods on those classes.
The multi methods provides a way to implement polymorphic extension methods.
In our case all of our EObject (superclass of all the semantic model classes) understand the "exec" message, but each particular class has its own implementation.
Lets start with some easy sentences implementation
Interpreting Movements (RIGHT, LEFT, FORWARD, etc)
So now we just need to implement the "exec()" method for this classes.
Here it is:
// moves
def dispatch void exec(LEFT l) { canvas.left(l.amount.evaluate) }
def dispatch void exec(RIGHT r) { canvas.right(r.amount.evaluate) }
def dispatch void exec(FORWARD f) {
canvas.forward(f.amount.evaluate.intValue)
}
def dispatch void exec(SET_X s) {
canvas.setX(s.amount.evaluate.intValue)
}
def dispatch void exec(SET_Y s) {
canvas.setY(s.amount.evaluate.intValue)
}
So on each type of movement we call a different method.
The interesting part is that we need to evaluate the "amount" field of the movement.
Because it could be a number, but it also could be a variable reference.
So basically we need to pass that object also through the interpreter.
This is a pretty common pattern. Probably all attributes of all the semantic class will need to eventually get evaluated by the interpreter.
So it's kind of a recursive pattern.
Evaluate() here is also an extension methods, with multiple dispatch.
Because different classes behave differently for evaluating them.
We will get back to evaluate() later.
If and Repeat statements
The if statement needs to evaluate its condition, and in case it is true, then execute all of its sentences.
This is exactly that behaviour in xtend code:
def dispatch void exec(^IF bif) {
if (bif.condition.evalBool)
bif.commands.forEach[c| c.exec ]
}
Again we are adding a "evalBool" method to the boolean condition.
Notice what's funny here is that this means that the Logo IF statement is implemented using Java/Xtend if statement. Which is obvious, but well, just something to be aware of.
As our interpreter is written in Java/Xtend then your language runtime can rely on already implemented functionality from the JVM, for example garbage collection, and also the stack execution model !
You don't need to write that up from scratch or implement.
At least for a language that shares the same execution model as JVM.
Here is the repeat implementation:
def dispatch void exec(REPEAT r) {
(1..(r.times.evaluate.intValue)).forEach[
r.commands.forEach[c| c.exec]
]
}
It uses xtend literals to create a range from 1 to "N" where N is the "times" property of the REPEAT object. Again that could be a value or a variable. So it needs to get evaluated.
Then for each of that it will execute all the sentences within the REPEAT.
As with the if, here we are basing the solution of the REPEAT on the "forEach" methods of xtend Iterables.
Boolean operations
Evaluating boolean operations is really straight forward since we use xtend operators.
Again we always need to first evaluate both operands and then natively compare them
def dispatch boolean evalBool(EQUALS e) {
e.op1.evaluate == e.op2.evaluate
}
def dispatch boolean evalBool(GREATER_THAN e) {
e.op1.evaluate > e.op2.evaluate
}
def dispatch boolean evalBool(LESSER_THAN e) {
e.op1.evaluate < e.op2.evaluate
}
Procedures
Now this is basically the most interesting part of the language.
We have seen that a Procedure is a piece of behaviour that can be called to reuse code (and of course to "reify this concept").
So a procedure can actually call another procedure, and so on.
Procedures receive parameters (PARAM). And within them you could have local variables (MAKE).
Like in any other language, each procedure defines a "scope" which contains all the references that is available within it. That means the "state" of the execution at that point.
So, when a procedure A, calls a procedure B, the code within B won't be able to modify or access the context of A. If A needs to send some data to B, then it must do it through parameters.
So, while executing A the available state is the current context that contains all A local variables plus its parameters..
Then when A calls B, the current context will be B's, and A will be hold back in background.
So when B finishes, the current context is now A again as it was.
This should be really familiar to you. It's the stack model.
So for our procedures, we need to implement that !
First thing is really easy: what happens when we evaluate a procedure definition, the TO class ?
def dispatch void exec(TO t) { /* does nothing. It's just a declaration */ }
Nothing, of course.
Because this is just the declaration. It's not executing it.
But then when we find a procedure call we need to implement the fun part:
def dispatch void exec(PROCEDURE_CALL call) {
stack.push(call.createContext())
call.to.commands.forEach[c | c.exec]
stack.pop
}
The code should be self-explained.
Executing a procedure is basically executing each of its commands (or statements).But before that we need to push the new context into the stack.
And after that popping it so we will use the previous context.
So our interpreter has a stack attribute besides the canvas
var stack = new Stack<Map<PARAM, Double>>
Notice that the stack is a map of PARAM and a Double.
This means that each stack element (context) has the declaration of the parameters, plus their actual values.
The part that changes is the value, the double.
So now we can see how the createContext() works:
def Map<PARAM,Double> createContext(PROCEDURE_CALL call) {
val map = newHashMap
// param - value
call.params.forEach[p, i|
map.put(call.to.parameters.get(i), p.evaluate)
]
map
}
To enter a procedure we create the context by creating a new Map evaluating the list of arguments from the call, to get their effective value, and then putting those values in the map (context) using the parameter at the same position from the Procedure declaration.
This is just one type of argument passing implementation.
It's based on the order of the parameters as many languages like Java, C#, C, etc.
Lets take this example, if you have this procedure
TO drawACircle :radius :center
...
END TO
Then when you call it you don't need to specify which parameter is the radius and which one is the center, because it uses the arg position as convention to match them
drawACircle 10 (4,4)
That is a LOGO language decision.
Your language could have a completely different mechanism.
For example named parameters.
In that case the "createContext" method implementation should be different and implement that mapping based on the names.
Now back to our example, the counter part of creating the context, is to "access" it.
If it holds the parameters, then it means that when you evaluate a reference to a parameter then it will go to the stack to fetch the current value.
def dispatch Double evaluate(PARAM p) { stack.peek.get(p) }
And there is the complete set of evaluate() multi methods:
def dispatch Double evaluate(VALUE v) { v.^val }
def dispatch Double evaluate(VARIABLE_REF r) { r.toVar.evaluate }
def dispatch Double evaluate(MAKE m) { m.value.evaluate }
def dispatch Double evaluate(PARAM p) { stack.peek.get(p) }
The first one is really easy, it is the case where you declared a double literal number.
A variable ref means to evaluate the referenciable.
As a referenciable could be a MAKE or a PARAM, then the other methods will be executed.
A MAKE evaluates the right side of the declaration, which will be a VALUE.
Variables (non param references state)
So we have seen that the parameters state are managed through a context which is in a stack.
So this is completely "out" of the semantic model objects. This means that the state is tracked by the interpreter and not the objects themselves.
This is one way to implement state changes, without touching the semantic model objects. Without mutating them.
We could have implemented variables also like that.
When we exec a variable declaration (MAKE) then it would have added a new key-value to the current context.
Then when you change that variable (for example with a SUM operation), this would have updated the variable, which would have meant to change the value in the context (the map).
But we didn't implemented that way.
Just to show that there's another way. A way where you hold the state in the semantic model itself.
You "change" it.
For example
MAKE a = 10
will create an instance of the class MAKE, with a "value" referencing the "10" object (instance of VALUE).
After that if you have this
SUM a = a + 3
Then we will change the "Make->10" object in order to start pointing to a new VALUE object that we must create with the value "13".
So we will modify the semantic model object directly.
Here is the interpreter logic for this:
def dispatch void exec(SUM s) { s.updateVar[a,b| a + b] }
def dispatch void exec(DIVIDE s) { s.updateVar[a,b| a / b] }
def dispatch void exec(MULTIPLY s) { s.updateVar[a,b| a * b] }
def dispatch void exec(SUBTRACT s) { s.updateVar[a,b| a - b] }
Again it relies on the native java operations. But the interesting part is the updateVar.
def updateVar(OPERATION s, (Double,Double)=>Double function) {
val newValue = function.apply(s.valOne.evaluate, s.valTwo.evaluate).asValue
s.targetVariable.value = newValue
}
Then it simply changes the targetVariable's "value" to point to the new value.
The next interesting part here is the "asValue" method, because the function returns a double object, but we cannot set a double to "targetVariable.value".
Which is the MAKE.value property, of type EXPRESSION.
So we need to create a new EXPRESSION object with the double number.
This is interesting because up until now we never created new instances of our semantic model.
All of the instances were created by Xtext itself based on the input file, while parsing it.
So if you need to create new objects you need to use a Factory class that is also automatically generated by XText.
def asValue(Double i) {
val v = TortugaDSLFactory.eINSTANCE.createVALUE
v.^val = i
v
}
We are here creating a new VALUE instance, which is a subclass of EXPRESSION, for simple values.
And that's it. We have created new "synthetic" objects. (because they don't have a corresponding element in the source code)
So accessing a variable value is just returning its property:
def dispatch Double evaluate(VALUE v) { v.^val }
Because that value will be changing through the execution of the program.
We don't need to get the value from the stack or any other place outside of the object itself.
To Sum-Up
So that's basically all. At least the important part of the interpreter.
There are some evaluation methods that we have ignored because they are basically the same mechanic.
To sum up we have seen here:
- That an xtext interpreter is just Java or xtend program that implements the runtime behaviour of your language (the runtime semantic)
- That if you do it in XTend you're be a lot happier than doing it in Java, since there are a couple of Xtend features that were actually designed to be useful for this case: extension methods, and multiple dispatch. To add behaviour to the semantic model classes, and to still have polymorphism without touching the generated classes
- The general mechanic of evaluating objects in an interpreter: which usually requires to recursively evaluate other objects of the graph, like attributes.
- That for some evaluations you just rely on java/xtend functionality like math operations, if, or loops.
- For more complex languages you need to implement the "state management" like we did for procedures call.
- We saw two different approach for state management: one that takes the state away of the semantic model (using a stack), and another that directly changes the semantic model objects
To generate code or to interpret
So to get back to our first posts. What would be better for your language: to generate code or to implement an interpreter ?
Of course there's not a single answer for this.
It depends.
By generating code you avoid implementing things like state management, and execution model.
Which could be complex for ready for production interpreted languages.
Although if your language has an execution model which is quite different from Java, then generating the code could also get difficult.
Generating code also introduces a new step in the execution, and indirection, which could make it difficult to map back runtime errors to the original code in your language.
While interpreted languages could be easier for this.
Still interpreters could also get complex and messy for complex languages.
The overall sensation is that implementing an interpreted feels like coding any other java/xtend program. It's just that you are writing a language execution model :P
But it's code, so you can use OOP technics like patterns, delegation, inheritance, etc.
While this is more complex or impossible for code generation. At least if you are using the "templates" approach.
So, it's completely up to you.
I think that it is a really good practice to try all 3 solutions to get the feeling of them.
While doing that you'll be learning by experience which is a lot better than just reading this blog post :)
So I hope you'll go ahead and start your own mini-language !
Have fun !
Tortuga Language Source code
You can find the source code of the language in github
Friday, 5 June 2015
Tutorial: Language Development with XText: A Logo example - Part I: Introduction to XText
Brief description of XText
XText is a Language Workbench. Meaning an environment for developing languages.
It targets from small Domain-Specific Languages (also known as DSL), to also complex General-Purpose Languages).
What's is good about it (well it has many good points) is that it gives you a pretty good base for quickly starting up a languages, by providing you advanced features only based on a declarative description of your language.
To give you an idea:
- you don't need to write a Lexer
- you don't need to write a Parser
- you don't need to write a code editor from scratch
- and so on..
It has pretty good defaults for almost all aspects of a language (like scoping and references).
So if if you already know XText at least at a basic level you know what I mean.
If you don't then I encourage you to read the following links:
- Main doc site: http://www.eclipse.org/Xtext/documentation/
- 5 min tutorial: http://www.eclipse.org/Xtext/documentation/101_five_minutes.html
- 15 min tutorial: http://www.eclipse.org/Xtext/documentation/102_domainmodelwalkthrough.html
If you happen to know Spanish then this link can be useful
Intro to XText
The grammar
The starting-point for an xtext language is a file called "the grammar".
It's kind of a BNF (Backus-Naur Form) declaration of the language, if you know what BNF is.
If you don't then don't worry (although I would highly recommend reading Naur papers about software development and the industry ;))
An xtext grammar is a file that is itself written in an specific format.
The goal of this grammar is to define two aspects of your language altogether:
- The Syntactical Form: allowed symbols of your language, and their order, spaces, keywords, etc.
- The Semantical Model: meaning the core "concepts" of your language and how they are composed. This will be represented as Class-based O.O. design. But you don't need to write those classes.
Let's put an example.
If you want to write a language for specifying products and their prices. The the syntax part could be defining keywords like: 'prod' , '$', etc.
But your concepts are: "a Product", "a Price", and the idea that "a Product has a current price".
Here is a sample grammar for the Hello example:

This tell us that a file for this language will contain a "Model"
The model has a list of "Greeting"
A Greeting has a name whose format is an "ID".

And indeed, XText generates this classes automatically for you. Actually interfaces.
Of course based on the grammar file.
Besides that you probably noticed that Greeting has some Strings there.
That's part of the syntax.
You read that Rule (Model and Greeting there are called "Rules") as follows in terms of syntax:
"A greeting is defined by the keyword 'Hello' then an ID you must provide and the a semi-colon".
This are valid examples of the DSL:
- Hello World !
- Hello Uqbar !
- Hello Project!
The Runtime Part
Just by defining the grammar XText will generate for you:
- The classes for your semantic model
- The parser, lexer and linker that will read a file and create instances of your semantic model
- A rich text editor with autocomplete, reference browsing and searches, syntax colouring
- An outline view
- And many extension points
Now what is up to you is what you want to do once the file is parsed into the semantic model.
I mean, what is supposed to do !
XText will parse the text into instances of your semantic model and then you choose what to do with it.
Here's a sample diagram (sorry it's in spanish)

For our example a file with greetings should write them to console ? should send an SMS ?
should publish them to Facebook ?
What ever.
That's what we call the runtime part of your language
And there's a whole new world there depending on the path you choose.
Basically with XText there are 3 options:

- Generating code
- Inferring (?) code
- Interpreting
We will discuss a little bit the first two options just to give you an idea, and the focus on the last one.
Since, the first two strategies are part of XText documentation and tutorials, but you won't find much info about XText Interpreted languages.
Languages that Generate Code
This first options is basically to go visiting all the object instances of your semantic model, once they have been parsed, and somehow generate executable code.
It's abstract like that, because you could generate:
- Textual code: for example java code, or C#, or python, or even C
- Binary code: directly executable code.
The first option allows you to use an already functional backend or Virtual Machine like the JVM, so you just get rid of a lot of work what would mean creating your own VM.

The bad part is that your language cannot be directly executed.
If you generate Java code then to run your program you will need three steps:
- Run the generator: which will produce .java code
- Compile the Java code
- Execute the compiled Java code

If you use an interpreted language like Python the just two:
- Run the generator: which will produce .py code
- Execute the Python interpreter
Anyway, the point is that you generate code.
How ?
For textual code, XText already provides you a way to do this implementing the IGenerator interface
- class MiGenerador implements IGenerator {
- override void doGenerate(Resource resource, IFileSystemAccess fsa) {
- for(e: resource.allContents.toIterable.filter(Model)) {
- ...
- }
- }
- }

Then like a templating engine you can write string expressions with dynamic parts using xtend RichStrings
- def compile(Entity e) '''
- package «e.eContainer.fullyQualifiedName»;
- public class «e.name» {
- }
- '''
The bad is that eventually if your language not "small" and you start to have a complex semantic model or complex rules for generating code, and you need to reuse templates, and stuff like that, then it tends to get messy an difficult to maintain.
Also (and this will make sense next when we'll see the second strategy), you could be generating invalid code and your generator could just not be aware about that.
It will explode on the user's face once it will try to run the generated code.
Think of types issues in the generated java code.
For example not importing classes, or incompatible types assignments, etc.
So...
The JVM Inferrer Model
The second strategy is also about generating code, but not any kind of code, but just Java code.
Yeap. Deal with that. You can also generate java code.
The good news is that you don't need to write the generator in Java. You'll use xtend.
And the end user of your language won't either write Java code, so, it's just a good an intermediate language to avoid writing something like assembler.
So, the JVM Inferrer also generates java code, but the way it does it is completely different.
You won't use code templates with just Strings.
You will use an API to generate code.
So you are not responsable of writing the code "text", but instead to map your semantic model into a model which represents the Java concepts like Class, Method, Field, etc.

The generator is also an xtend class which implements a given interface
- class DomainmodelJvmModelInferrer implements IJvmModelInferrer {
- override void infer(EObject model, IJvmDeclaredTypeAcceptor acceptor, boolean preIndexPhase) {
- ...
- }
- }
Here's a code snippet which based on an object instanceof Operation from the semantic model it generates a field, a getter and a setter for it as members of a class that is currently generating
- Property : {
- members += feature.toField(feature.name, feature.type)
- members += feature.toGetter(feature.name, feature.type)
- members += feature.toSetter(feature.name, feature.type)
- }
There are number of advantages of using this inferrer or mapper
The first one is that it's now code, and you have an API which models all the Java source concepts, so you should be able to design complex code generation logic by applying all the OOP good practices.
But also, the most important part is that XText will keep a link between the Java generated code and the semantic model which generated that part of the code.
In this case XText will know that the generated field, getter and setters where derived from a particular instance of your semantic model.
And even better XText knows given a semantic model instance from which part of the text came from.
So, it is really clever, and when it detects that the generated java code has a problem (like a compilation error we mentioned before), it will point out the original piece of code that the user wrote.
It will also do more complex features like inferring types from the generated java code and then applying validations back to your language. So it will avoid the user writing code that won't compile in the Java code.
You need to see it with your own eyes. Go there and follow their docs here
There are also some examples of this strategy.
Otherwise we will create a new tutorial in the future :)
Interpreted Languages
The last strategy is to completely avoid generating code.
We say, Xtext is a Java framework, and it's already instantiating Java objects for our semantic model. We have those objects there available from java, so instead of visiting them to generate code, why don't we just visit them to perform the actual execution ?
For example for each Greeting, we will print it to console through System.out.println().
And that's basically the interpreted model.
You'll basically need something like a Main class which will receive the file path that you want to interpret.
It will call Xtext to parse this file into Semantic Model instances, and then go through it to interpret it and do something

This is the strategy that we will focus on for the LOGO example.
The advantages of it is that:
- there's no intermediate language
- no extra commands or step to execute
- at first and if the language is simple, then the interpreter is a really good way to have something working right away.
The disadvantages are more difficult to explain right now. We will wait for the end of the post.
But basically it's the fact that the semantic model are not 100% "your classes". They are generated so you cannot touch them. And that adds complexity. That won't allow you to fully desing with OOP (although XText has many cool features for tackling that like multi methods and extension methods).
Also you are using directly those objects that are kind of AST objects. They are tied to all the eCore and EMF infrastructure.
So you cannot instantiate them easily. This means that your language core classes are tied up to eclipse technology and frameworks.
There's also a runtime overhead there (plugins, dependencies, eclipse, osgi, etc).
Thursday, 4 June 2015
Tutorial: Language Development with XText: A Logo example - Part II: Getting to Know Logo and Our Solution Approach
A Little of Context
This language was developed as an example language to teach DSLs in the context of Public University subject in Argentina for which some of us are teachers.
We wanted to show a small yet powerful interpreted language.
And one of the goal was to shows something that will produce some visual effect, so that the student could really appreciate the execution of the language.
But we didn't want to actually spend a lot of time on the graphical part, creating a logo from scratch
So we just went ahead and searched on Google for an existing Logo project, which was JVM compatible.
We will just then create the XText language and use an interpreter to read or semantic model and call that Logo to perform the drawing.
That was exactly what we did.
Tortue
So as backend logo we used Tortue a GPL open source project
Here's a screenshot from their site

It actually comes as a full standalone java app.
But we will just use the classes as if it was an API.
And also make him draw into a canvas that we will embed into the running eclipse.
The Language Grammar
The logo language is kind of mid-sized. It's not a so small as a common DSL, but it is neither much complex or big as a typed GPL language.
Still it is a good exercise since it has many elements of a full blown GPL imperative language like C, pascal, Java, etc.
We will see here a couple of example programs to understand the language:
Moving the Turtle
This is a really simple program to start getting familiar with the language
PENDOWN
FORWARD 80
RIGHT 90
FORWARD 80
RIGHT 90
FORWARD 80
RIGHT 90
FORWARD 80
PENUP

It will draw the following:

They have side-effect, meaning that they change the state of the turtle to "drawing" or just "moving without drawing".
The the others: RIGHT, LEFT, FORWARD, are Move operations for controlling the turtle.
So, to start seeing some xtext code here is a rule that put together all these moves
MOVE:
FORWARD | LEFT | RIGHT | SET_X | SET_Y
;
This is part of our new language grammar in Xtext.
We will see each actual rule in the next section.Using variables
Now we can change the previous program to avoid repeating the size of each side of the square, using a variable.
PENDOWN
MAKE lado = 80
FORWARD lado
RIGHT 90
FORWARD lado
RIGHT 90
FORWARD lado
RIGHT 90
FORWARD lado
PENUP
The variable "lado" (spanish for "side") is declared through the keyword "MAKE" which assigns a name and an initial value to it.
Then we can see that all other operations like FORWARD could either use a simple value like a Number or a Variable Reference.
So now we can see the rules for these operations:
FORWARD: 'FORWARD' amount=EXPRESSION;
LEFT: 'LEFT' amount=EXPRESSION;
RIGHT: 'RIGHT' amount=EXPRESSION;
SET_X: 'SETX' amount=EXPRESSION;
SET_Y: 'SETY' amount=EXPRESSION;
We can see there that all of these rules expect a special keyword and then an EXPRESSION.
Which in turn is as we identified:
EXPRESSION:
VARIABLE_REF | VALUE
;
A value is simply a double number
VALUE:
val=DOUBLE
;
And a Variable reference is a little bit more complicated:
VARIABLE_REF: toVar=[REFERENCIABLE];
It is a reference (the syntax for that in xtext is to use the square brackets) to a REFERENCIABLE.
A Referenciable is:
REFERENCIABLE:
MAKE | PARAM
;
So this means that a referencia is a one of those variables or a PARAM, which we haven't seen yet.
But we will soon !
Repeat Loops
We can still simplify the example by reducing duplicated code, using a repeat loop.
PENDOWN
MAKE lado = 100
REPEAT 4
FORWARD lado
RIGHT 90
END REPEAT
PENUP
Lets see the grammar rules for this:
REPEAT:
'REPEAT' times=EXPRESSION
(commands+=SENTENCE)+
'END REPEAT'
;
Because "times" is of type EXPRESSION. Which we already see could be a VARIABLE_REF or a Variable.
This means you can do this
MAKE sides = 4
REPEAT sides
FORWARD lado
RIGHT 90
END REPEAT
We will go a little further fast with this one.
SENTENCE:
MAKE | CONTENT
| PROCEDURE_CALL
| OPERATION
| CONTROL_SENTENCES
| MOVE
| DRAWING_SENTENCE
Sentence is probably the most generic rule, since it could be one of the MOVE sentences that we already saw, to control the turtle movement, but also a DRAWING_SENTENCE, that we also saw. It could also be a MAKE, because you can define new variables within a REPEAT, for example.
And then more stuff we haven't seen yet like: PROCEDURE_CALL, CONTROL_SENTENCES, CONTENT, and OPERATION.
We will see each of them in further sections
Procedures
Our sample program draws a square, but if we want to draw many squares, we don't want to copy and paste that code, so, for reusing certain functionality we can define procedures, than can be called anytime.
TO makeASquare
PENDOWN
MAKE lado = 100
REPEAT 4
FORWARD lado
RIGHT 90
END REPEAT
PENUP
END TO
makeASquare
makeASquare
This program first defines a procedure named "makeASquare" and all of its sentences.
Then the program itself has two procedure calls to the same procedure.
So we have two new concepts for the language.
A procedure definition, which is:
TO:
'TO' name=ID (parameters+=PARAM)*
(commands+=SENTENCE)+
'END TO'
;
Notice that it could have a list of PARAM's. And the body is a list of SENTENCE's (we've already seen that it's basically "anything" -but not a procedure definition, you cannot define one within other-)
A param is:
PARAM:
':' name=ID
;
So now we now that from a REPEAT or a FORWARD, RIGHT, etc, you can use a value (double) or reference either a variable (MAKE), or a PARAM, in case you are within a procedure !.
The other new concept is the procedure call:
PROCEDURE_CALL:
to=[TO] (params+=EXPRESSION)*
;
Easy, a reference to a procedure (TO), and then an optional list of EXPRESSION, which will be evaluated and passed as the values for each parameter.
Remember EXPRESSION is either a value or a reference (to MAKE or PARAM).
Some Other Syntax Elements
There are a couple of other secondary elements in the language for example to control the font and the line color
PENCOLOR GREEN
makeASquare
Will produce:

CLEAR
HOME
CANVASCOLOR BLACK
FONTSIZE 36
FONTSTYLE BOLD
DRAWSTRING "THIS IS TORTUE TEXT"
Clear of course will erase the canvas. And home will move the turtle to the starting point (center)
Canvas color will set the background color.
Drawstring is as you probably guessed to write a text.
Here's a cool sample app which combines it with PEN COLOR
CLEAR
FONTSIZE 36
FONTSTYLE BOLD
SETX 140
MAKE color = 10
REPEAT 24
PENCOLOR color 0 color 50
LEFT 15
PENUP
FORWARD 45
PENDOWN
DRAWSTRING "THIS IS TORTUE TEXT"
SUM color = color + 10
END REPEAT
This produces the following image:

Cool ah ?
Thanks Tortue :P
Operations
There are a couple of simple mathematical operations to work with numbers.
DIVIDE blue = color / 2
All of this operations have two effects:
- Compute a value (on the right)
- Assigns that value into a variable (using a reference)
Here are the others:
SUM forwardamount = i + 1
MULTIPLY green = J * I
Here is a sample program which uses SUM
CLEAR
HOME
MAKE i = 1
MAKE color = 200
REPEAT 500
MAKE red = color
DIVIDE blue = color / 2
MAKE green = color
PENCOLOR red green blue 255
MAKE forwardamount = 0
SUM forwardamount = i + 1
FORWARD forwardamount
RIGHT 70
SUM i = i + 1
SUM color = color + 1
IF color > 255
// MAKE color = 200
SUM color = 0 + 200
END IF
END REPEAT
It draws the following:

Lets check the grammar:
OPERATION:
SUM
| SUBTRACT
| MULTIPLY
| DIVIDE
;
And they are all pretty similar:
SUM:
'SUM' targetVariable=[MAKE] '=' valOne=EXPRESSION '+' valTwo=EXPRESSION;
SUBTRACT:
'SUBTRACT' targetVariable=[MAKE] '=' valOne=EXPRESSION '-' valTwo=EXPRESSION;
MULTIPLY:
'MULTIPLY' targetVariable=[MAKE] '=' valOne=EXPRESSION '*' valTwo=EXPRESSION;
DIVIDE:
'DIVIDE' targetVariable=[MAKE] '=' valOne=EXPRESSION '/' valTwo=EXPRESSION;
Basically it has a variable reference. Notice that we don't use REFERENCIABLE here, so this means that you can only use MAKE variables and not PARAM. This means that you cannot reassign PARAMeters.
Then on the right part they are all binary operations, so they have two operands. Each operand is not exclusively a double number but an EXPRESSION.
So that you can SUM 2 with 2, but also 2 + a, or "a + b"
If
You should be getting the idea, this is just more of the same.
IF color > 255
// MAKE color = 200
SUM color = 0 + 200
END IF
This is the grammar for the if
IF:
'IF' condition=BOOLEAN_EXPRESSION
(commands+=SENTENCE)+
'END IF'
;
And something cool appears here, the BOOLEAN_EXPRESSION's.
BOOLEAN_EXPRESSION:
EQUALS
| GREATER_THAN
| LESSER_THAN
EQUALS: op1=EXPRESSION '=' op2=EXPRESSION;
GREATER_THAN: op1=EXPRESSION '>' op2=EXPRESSION;
LESSER_THAN: op1=EXPRESSION '<' op2=EXPRESSION;
And that's it.
This is pretty much all the syntax of the language
Full Tortue Syntax and Commands
For the complete syntax reference of Tortue you can visit:
Next
In the next part we will start to look at the interpreter and how to give some execution meaning to this grammar :)
Subscribe to:
Comments (Atom)