
In this post we will show an example Interpreter for the Logo language, for which we have already seen its set of instructions and its xtext grammar in the second post.
So now we will see the interpreter's code.
But before that
Overview of the Logo Semantic Model
Lets analyse a little bit what's a logo program once it has been parsed and validated and then the semantic model instances are created.
For that it's useful to understand the classes XText generated.
Here's a full class diagram of the semantic model.

Here's a full class diagram of the semantic model.
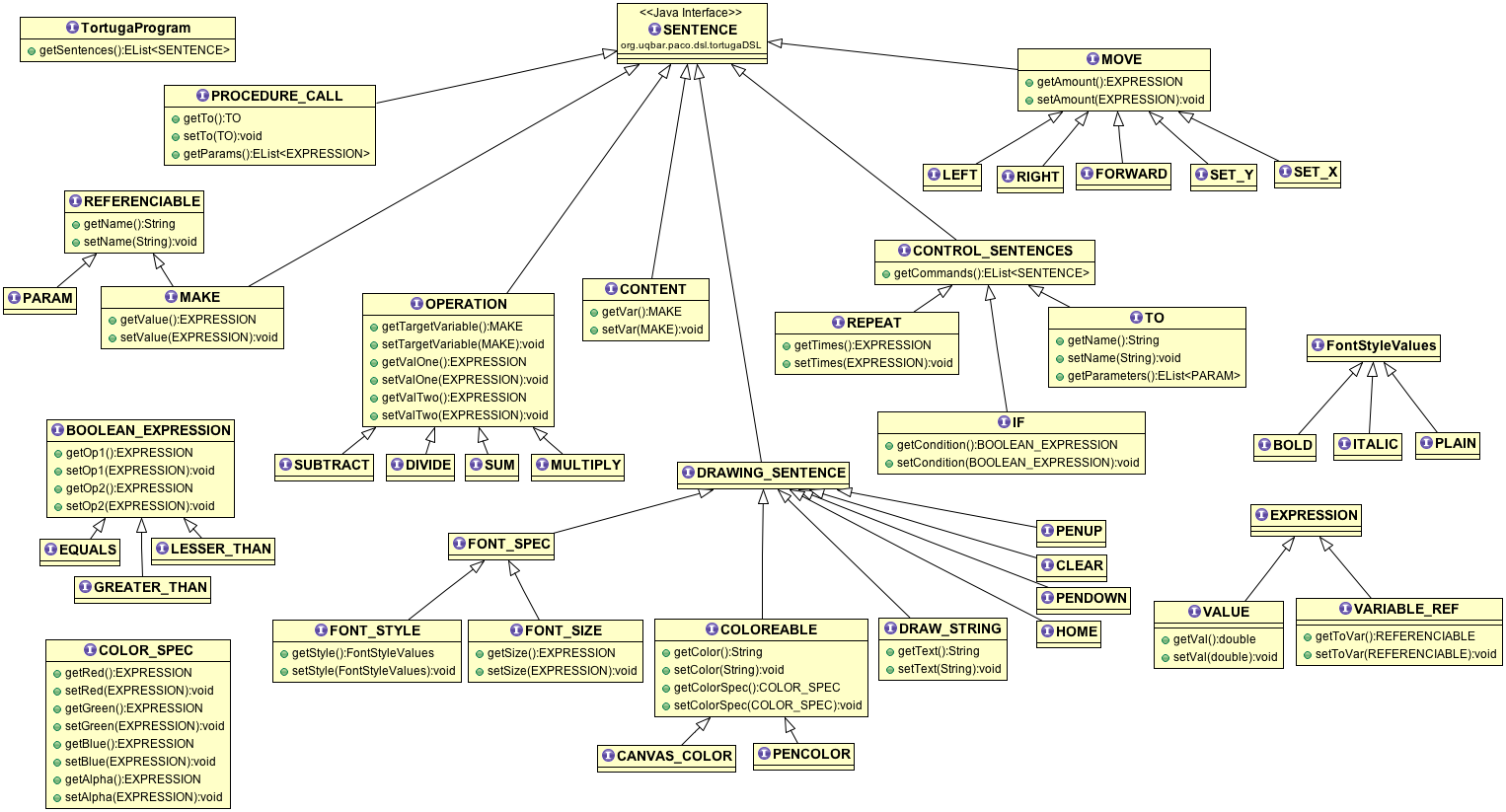
The root element is the TortugaProgram (the first grammar rule).
A program has a list of SENTENCES (grr.. to comply with the syntax we defined rules that are uppercased and now they just don't follow the standard java class names).
Then there are a couple of different SENTENCES like REPEAT, IF, MAKE, etc.
The Interpreter
What's an interpreter ?
In its simplest way, an interpreter for an XText language is just a class that, given an input file:
- Calls XText so that it parses the file (validating and linking) and returns back an instance of the root model (TortugaProgram in our case)
- Then does something with those objects
It could be a simple class with a Main.
class MyInterpreter {
def static void main(String[] args) {
val fileName = args.get(0)
val uri = URI.createURI(fileName)
val injector = new MyDslStandaloneSetup().createInjectorAndDoEMFRegistration
val resourceSet = injector.getInstance(XtextResourceSet)
val resource = resourceSet.createResource(uri)
resource.load(#{})
val model = resource.contents.get(0) as MyModel
new MyInterpreter().interpret(model)
}
def void interpret(MyModel model) {
// DO SOMETHING HERE ...
}
}
Then you could package it along with all its dependencies (that would need a new blog post) and then anyone could use it like:
java -cp .... classpath_here... org.uqbar.tutorial.xtext.MyInterpreter myFile.tortu
You could also provide a script to hide away the java command
./logo myFile.tortu
Integrating it into Eclipse
Instead of creating a Main class for headless execution, as the interpreter is just java code, you could integrate it with the Eclipse IDE, so that one can use the text editor for writing code in your language and then just "run" it from the IDE itself.
This can be done by extending an specific eclipse extension point for launch shortcuts (in case you want to show it as part of the "Run" menu), providing a class, icon, and a filter so that it will only apply for your language file extension.
Here is a sample xml from our plugin.xml
<extension
point="org.eclipse.debug.ui.launchShortcuts">
<shortcut
class="org.uqbar.paco.dsl.ui.TortugaDSLExecutableExtensionFactory:org.uqbar.paco.dsl.tortuga.ui.launch.LaunchTortugaShortcut"
icon="icons/tortuga.png"
id="org.uqbar.paco.dsl.tortuga.ui.launchTortuga"
label="Tortuga"
modes="run">
<contextualLaunch>
<enablement>
<with variable="selection">
<count value="1"/>
<iterate
ifEmpty="false"
operator="and">
<adapt type="org.eclipse.core.resources.IFile"/>
<test property="org.eclipse.debug.ui.matchesPattern"
value="*.tortu"/>
</iterate>
</with>
</enablement>
<contextLabel
mode="run"
label="Run Tortuga"/>
</contextualLaunch>
</shortcut>
</extension>
And then the Launch class has code similar to the main we have seen, but delegates the actual interpreting logic to an interpreter class.
class LaunchTortugaShortcut implements ILaunchShortcut {
@Inject
private IResourceForEditorInputFactory resourceFactory;
override launch(ISelection selection, String mode) { }
override launch(IEditorPart editor, String mode) {
val input = editor.editorInput
if (editor instanceof XtextEditor && input instanceof FileEditorInput) {
val resource = resourceFactory.createResource(input)
resource.load(newHashMap())
val program = resource.contents.head as TortugaProgram
new TortugaInterpreter(canvas).exec(program)
}
}
def getCanvas() {
TortugaView.getInstance.canvas
}
}
It basically gets the current editor's file and then calls Xtext to load it, which will do all the parsing and validation.
With the model parsed into a TortugaProgram, it creates a new TortugaInterpreter and executes the program.
In our case the interpreter receives a Canvas in which Tortue will paint.
That's all for the skeleton of our interpreter.
The interpreter itself
Now we need to implement the execution (the runtime semantic) for each of the classes of our semantic model.
Let's start from top to down
Interpreter class and evaluating the root model
Interpreting a Logo program would be basically to execute each of its sentences.
So here's a sample implementation:
class TortugaInterpreter {
TortueCanvas canvas
new(TortueCanvas canvas) {
this.canvas = canvas;
}
def dispatch void exec(TortugaProgram p) {
canvas.newCommand
p.sentences.forEach[s | s.exec ; canvas.repaint ]
}
// ******************************
// ** EXECs: here one multi method per SENTENCE CLASS
// ******************************
def dispatch exec(...) { ... }
def dispatch exec(...) { ... }
def dispatch exec(...) { ... }
}
What we see here is that evaluating a TortugaProgram is to:
- reset the canvas
- evaluate each of the "sentences"
We can see that we are using multiple dispatch methods.
This is a pretty cool feature of xtend that is really useful for language interpreters along with extension methods.
Since we cannot touch the semantic model classes because they are generated, we will use extension methods, to add behaviour to them, and use it as if they were methods on those classes.
The multi methods provides a way to implement polymorphic extension methods.
In our case all of our EObject (superclass of all the semantic model classes) understand the "exec" message, but each particular class has its own implementation.
Lets start with some easy sentences implementation
Interpreting Movements (RIGHT, LEFT, FORWARD, etc)
So now we just need to implement the "exec()" method for this classes.
Here it is:
// moves
def dispatch void exec(LEFT l) { canvas.left(l.amount.evaluate) }
def dispatch void exec(RIGHT r) { canvas.right(r.amount.evaluate) }
def dispatch void exec(FORWARD f) {
canvas.forward(f.amount.evaluate.intValue)
}
def dispatch void exec(SET_X s) {
canvas.setX(s.amount.evaluate.intValue)
}
def dispatch void exec(SET_Y s) {
canvas.setY(s.amount.evaluate.intValue)
}
So on each type of movement we call a different method.
The interesting part is that we need to evaluate the "amount" field of the movement.
Because it could be a number, but it also could be a variable reference.
So basically we need to pass that object also through the interpreter.
This is a pretty common pattern. Probably all attributes of all the semantic class will need to eventually get evaluated by the interpreter.
So it's kind of a recursive pattern.
Evaluate() here is also an extension methods, with multiple dispatch.
Because different classes behave differently for evaluating them.
We will get back to evaluate() later.
If and Repeat statements
The if statement needs to evaluate its condition, and in case it is true, then execute all of its sentences.
This is exactly that behaviour in xtend code:
def dispatch void exec(^IF bif) {
if (bif.condition.evalBool)
bif.commands.forEach[c| c.exec ]
}
Again we are adding a "evalBool" method to the boolean condition.
Notice what's funny here is that this means that the Logo IF statement is implemented using Java/Xtend if statement. Which is obvious, but well, just something to be aware of.
As our interpreter is written in Java/Xtend then your language runtime can rely on already implemented functionality from the JVM, for example garbage collection, and also the stack execution model !
You don't need to write that up from scratch or implement.
At least for a language that shares the same execution model as JVM.
Here is the repeat implementation:
def dispatch void exec(REPEAT r) {
(1..(r.times.evaluate.intValue)).forEach[
r.commands.forEach[c| c.exec]
]
}
It uses xtend literals to create a range from 1 to "N" where N is the "times" property of the REPEAT object. Again that could be a value or a variable. So it needs to get evaluated.
Then for each of that it will execute all the sentences within the REPEAT.
As with the if, here we are basing the solution of the REPEAT on the "forEach" methods of xtend Iterables.
Boolean operations
Evaluating boolean operations is really straight forward since we use xtend operators.
Again we always need to first evaluate both operands and then natively compare them
def dispatch boolean evalBool(EQUALS e) {
e.op1.evaluate == e.op2.evaluate
}
def dispatch boolean evalBool(GREATER_THAN e) {
e.op1.evaluate > e.op2.evaluate
}
def dispatch boolean evalBool(LESSER_THAN e) {
e.op1.evaluate < e.op2.evaluate
}
Procedures
Now this is basically the most interesting part of the language.
We have seen that a Procedure is a piece of behaviour that can be called to reuse code (and of course to "reify this concept").
So a procedure can actually call another procedure, and so on.
Procedures receive parameters (PARAM). And within them you could have local variables (MAKE).
Like in any other language, each procedure defines a "scope" which contains all the references that is available within it. That means the "state" of the execution at that point.
So, when a procedure A, calls a procedure B, the code within B won't be able to modify or access the context of A. If A needs to send some data to B, then it must do it through parameters.
So, while executing A the available state is the current context that contains all A local variables plus its parameters..
Then when A calls B, the current context will be B's, and A will be hold back in background.
So when B finishes, the current context is now A again as it was.
This should be really familiar to you. It's the stack model.
So for our procedures, we need to implement that !
First thing is really easy: what happens when we evaluate a procedure definition, the TO class ?
def dispatch void exec(TO t) { /* does nothing. It's just a declaration */ }
Nothing, of course.
Because this is just the declaration. It's not executing it.
But then when we find a procedure call we need to implement the fun part:
def dispatch void exec(PROCEDURE_CALL call) {
stack.push(call.createContext())
call.to.commands.forEach[c | c.exec]
stack.pop
}
The code should be self-explained.
Executing a procedure is basically executing each of its commands (or statements).But before that we need to push the new context into the stack.
And after that popping it so we will use the previous context.
So our interpreter has a stack attribute besides the canvas
var stack = new Stack<Map<PARAM, Double>>
Notice that the stack is a map of PARAM and a Double.
This means that each stack element (context) has the declaration of the parameters, plus their actual values.
The part that changes is the value, the double.
So now we can see how the createContext() works:
def Map<PARAM,Double> createContext(PROCEDURE_CALL call) {
val map = newHashMap
// param - value
call.params.forEach[p, i|
map.put(call.to.parameters.get(i), p.evaluate)
]
map
}
To enter a procedure we create the context by creating a new Map evaluating the list of arguments from the call, to get their effective value, and then putting those values in the map (context) using the parameter at the same position from the Procedure declaration.
This is just one type of argument passing implementation.
It's based on the order of the parameters as many languages like Java, C#, C, etc.
Lets take this example, if you have this procedure
TO drawACircle :radius :center
...
END TO
Then when you call it you don't need to specify which parameter is the radius and which one is the center, because it uses the arg position as convention to match them
drawACircle 10 (4,4)
That is a LOGO language decision.
Your language could have a completely different mechanism.
For example named parameters.
In that case the "createContext" method implementation should be different and implement that mapping based on the names.
Now back to our example, the counter part of creating the context, is to "access" it.
If it holds the parameters, then it means that when you evaluate a reference to a parameter then it will go to the stack to fetch the current value.
def dispatch Double evaluate(PARAM p) { stack.peek.get(p) }
And there is the complete set of evaluate() multi methods:
def dispatch Double evaluate(VALUE v) { v.^val }
def dispatch Double evaluate(VARIABLE_REF r) { r.toVar.evaluate }
def dispatch Double evaluate(MAKE m) { m.value.evaluate }
def dispatch Double evaluate(PARAM p) { stack.peek.get(p) }
The first one is really easy, it is the case where you declared a double literal number.
A variable ref means to evaluate the referenciable.
As a referenciable could be a MAKE or a PARAM, then the other methods will be executed.
A MAKE evaluates the right side of the declaration, which will be a VALUE.
Variables (non param references state)
So we have seen that the parameters state are managed through a context which is in a stack.
So this is completely "out" of the semantic model objects. This means that the state is tracked by the interpreter and not the objects themselves.
This is one way to implement state changes, without touching the semantic model objects. Without mutating them.
We could have implemented variables also like that.
When we exec a variable declaration (MAKE) then it would have added a new key-value to the current context.
Then when you change that variable (for example with a SUM operation), this would have updated the variable, which would have meant to change the value in the context (the map).
But we didn't implemented that way.
Just to show that there's another way. A way where you hold the state in the semantic model itself.
You "change" it.
For example
MAKE a = 10
will create an instance of the class MAKE, with a "value" referencing the "10" object (instance of VALUE).
After that if you have this
SUM a = a + 3
Then we will change the "Make->10" object in order to start pointing to a new VALUE object that we must create with the value "13".
So we will modify the semantic model object directly.
Here is the interpreter logic for this:
def dispatch void exec(SUM s) { s.updateVar[a,b| a + b] }
def dispatch void exec(DIVIDE s) { s.updateVar[a,b| a / b] }
def dispatch void exec(MULTIPLY s) { s.updateVar[a,b| a * b] }
def dispatch void exec(SUBTRACT s) { s.updateVar[a,b| a - b] }
Again it relies on the native java operations. But the interesting part is the updateVar.
def updateVar(OPERATION s, (Double,Double)=>Double function) {
val newValue = function.apply(s.valOne.evaluate, s.valTwo.evaluate).asValue
s.targetVariable.value = newValue
}
Then it simply changes the targetVariable's "value" to point to the new value.
The next interesting part here is the "asValue" method, because the function returns a double object, but we cannot set a double to "targetVariable.value".
Which is the MAKE.value property, of type EXPRESSION.
So we need to create a new EXPRESSION object with the double number.
This is interesting because up until now we never created new instances of our semantic model.
All of the instances were created by Xtext itself based on the input file, while parsing it.
So if you need to create new objects you need to use a Factory class that is also automatically generated by XText.
def asValue(Double i) {
val v = TortugaDSLFactory.eINSTANCE.createVALUE
v.^val = i
v
}
We are here creating a new VALUE instance, which is a subclass of EXPRESSION, for simple values.
And that's it. We have created new "synthetic" objects. (because they don't have a corresponding element in the source code)
So accessing a variable value is just returning its property:
def dispatch Double evaluate(VALUE v) { v.^val }
Because that value will be changing through the execution of the program.
We don't need to get the value from the stack or any other place outside of the object itself.
To Sum-Up
So that's basically all. At least the important part of the interpreter.
There are some evaluation methods that we have ignored because they are basically the same mechanic.
To sum up we have seen here:
- That an xtext interpreter is just Java or xtend program that implements the runtime behaviour of your language (the runtime semantic)
- That if you do it in XTend you're be a lot happier than doing it in Java, since there are a couple of Xtend features that were actually designed to be useful for this case: extension methods, and multiple dispatch. To add behaviour to the semantic model classes, and to still have polymorphism without touching the generated classes
- The general mechanic of evaluating objects in an interpreter: which usually requires to recursively evaluate other objects of the graph, like attributes.
- That for some evaluations you just rely on java/xtend functionality like math operations, if, or loops.
- For more complex languages you need to implement the "state management" like we did for procedures call.
- We saw two different approach for state management: one that takes the state away of the semantic model (using a stack), and another that directly changes the semantic model objects
To generate code or to interpret
So to get back to our first posts. What would be better for your language: to generate code or to implement an interpreter ?
Of course there's not a single answer for this.
It depends.
By generating code you avoid implementing things like state management, and execution model.
Which could be complex for ready for production interpreted languages.
Although if your language has an execution model which is quite different from Java, then generating the code could also get difficult.
Generating code also introduces a new step in the execution, and indirection, which could make it difficult to map back runtime errors to the original code in your language.
While interpreted languages could be easier for this.
Still interpreters could also get complex and messy for complex languages.
The overall sensation is that implementing an interpreted feels like coding any other java/xtend program. It's just that you are writing a language execution model :P
But it's code, so you can use OOP technics like patterns, delegation, inheritance, etc.
While this is more complex or impossible for code generation. At least if you are using the "templates" approach.
So, it's completely up to you.
I think that it is a really good practice to try all 3 solutions to get the feeling of them.
While doing that you'll be learning by experience which is a lot better than just reading this blog post :)
So I hope you'll go ahead and start your own mini-language !
Have fun !
Tortuga Language Source code
You can find the source code of the language in github
No comments:
Post a Comment